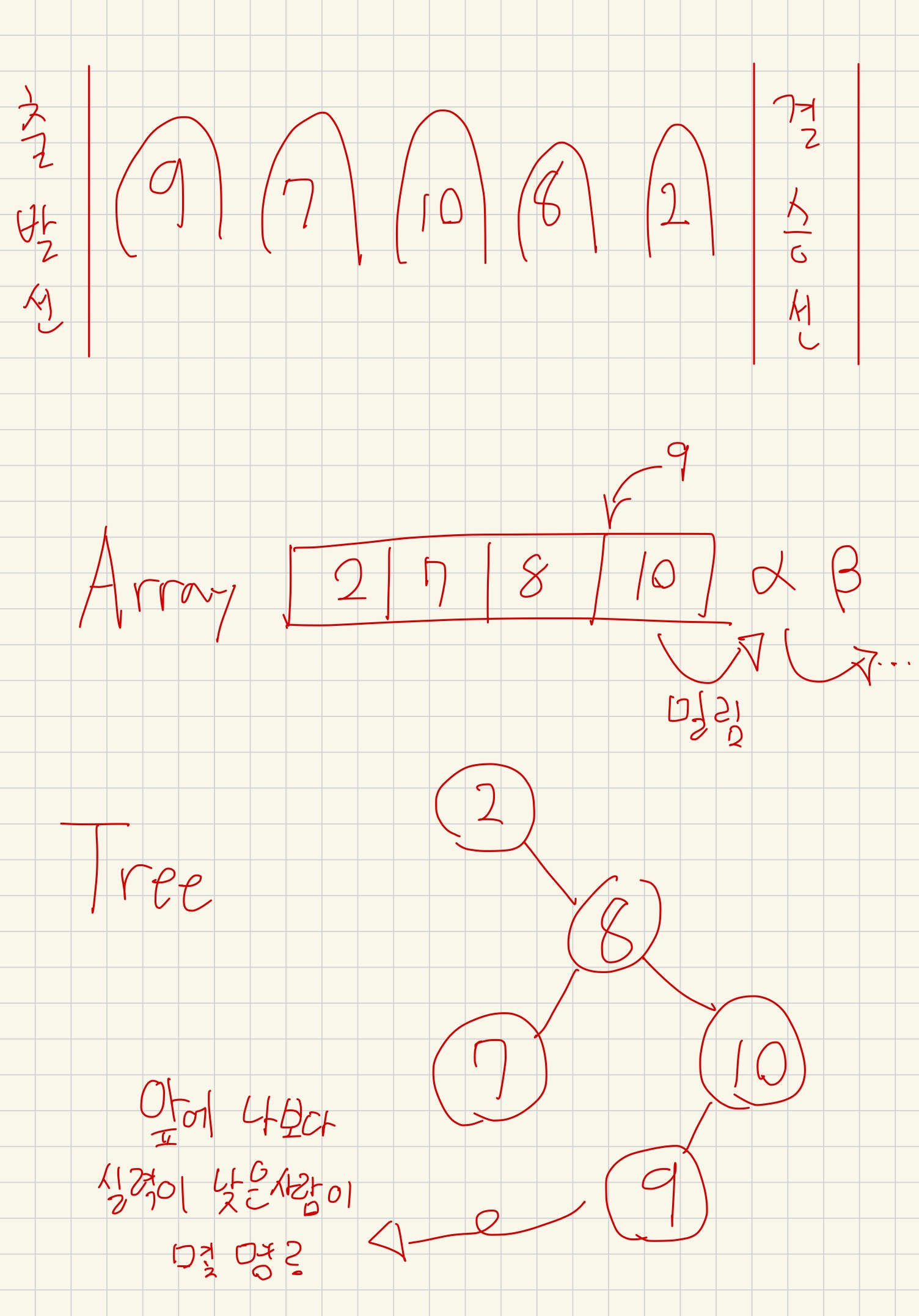
매일 상상만 하던 random access + O(logN) 삽입 삭제가 이미 있다니 . . (only g++) #include #include #include using namespace __gnu_pbds; using namespace std; #define ordered_set tree int main(){ ordered_set oSet; // idx 번째 iterator 반환 oSet.find_by_order(idx); // value의 idx를 반환 (value보다 작은 원소 개수를 반환) oSet.order_of_key(value); oSet.insert(v); oSet.erase(v); } 활용 https://www.acmicpc.net/problem/2517 2517번: 달리기 첫째 줄에는..